Benchmark
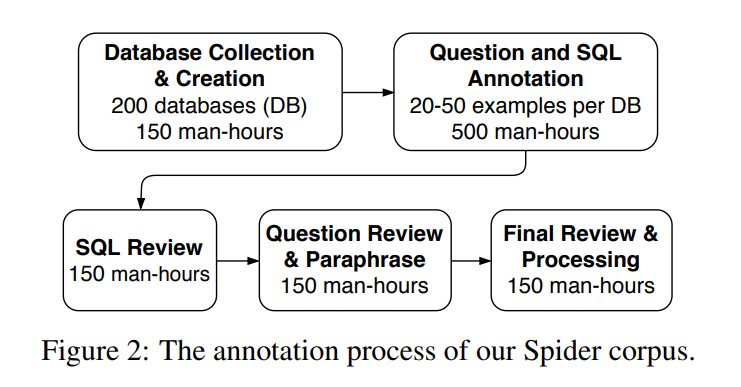
Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task
DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation
TimelineQA: A Benchmark for Question Answering over Timelines
Large Language Models of Code Fail at Completing Code with Potential Bugs
Dataset
A parallel corpus of Python functions and documentation strings for automated code documentation and code generation
- (python function, docstring) pairs scraped from Github.
Program Synthesis with Large Language Models
MathQA: Towards Interpretable Math Word Problem Solving with Operation-Based Formalisms
Table Pre-training: A Survey on Model Architectures, Pre-training Objectives, and Downstream Tasks
Tabular dataset
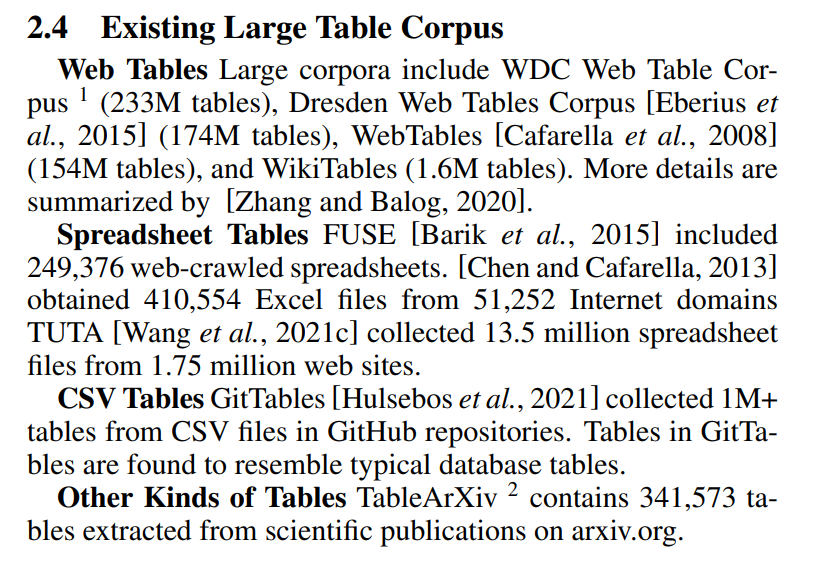
GitTables: A Large-Scale Corpus of Relational Tables
- extract 1M CSV tables from Github
The Stack: 3 TB of permissively licensed source code
Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only