Fine-tuning BART to do data preparation tasks:
Data preparation — including data cleaning, data transformation, entity resolution, information extraction, and so forth
- encoder-decoder architecture, masked prediction
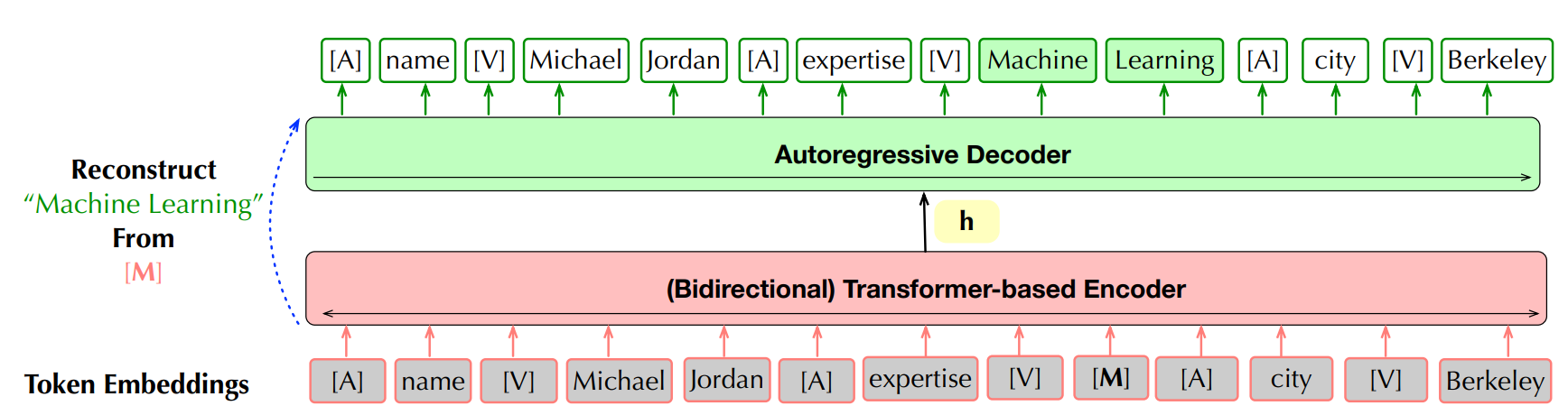
- use BART as baseline, evaluate on some unseen tables from Google and Amazon. Mask some cells and values on the table. Then use model to predict the value. Use f1 score as metric.
GitTables: A Large-Scale Corpus of Relational Tables
- extract 1M CSV tables from Github
- use nltk.wordnet as key words to search CSV files in Github
Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes

- Use LLM to extract tabular data from semi-structured data (e.g. HTML webpages, PDFs, text)
- methods:
- Direct Extraction: costly,
- Code Synthesis: use different prompts to generate more functions and aggregate them.
- Use Pair F1 as metric
Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation
- improve HUMANEVAL with more test cases and correct the ground truth program
- prompt ChatGPT to generate more test cases
- use type-aware mutation to generate more test cases(something like do small changes on existing test cases)
Thinking: prompt to synthesize programs with random function which then are used to generate test cases.
DocPrompting: Generating Code by Retrieving the Docs
- retrieve documentation of functions and libraries as prompts to help code synthesis.
Binding Language Models in Symbolic Languages
- prompt CodeX to generate SQL/Python programs over tables, then execute them to get the result
- two steps: use in-context learning to generate rough programs with some questions(prompt CodeX again to solve it)
- use the first three line of a table in prompt.
- fixed in-context learning or use SentenceBERT and similarity to find the top-k relavent one.
A Static Evaluation of Code Completion by Large Language Models
- do evaluation using Abstract Syntax Trees
Textbooks Are All You Need
- phi-1 model
- only trained on textbook quality data