CodeBERT
- Transformer based bidirection model
- two training objective:
- masked language modeling
- replaced token detection (mask first; use n-gram to fill the masked position, then ask the model to predict whether the token is replaced or original)
- curate a multi-choice benchmark(only max and min), ask the model to fill the masked position.
SemSup-XC: Semantic Supervision for Zero and Few-shot Extreme Classification
- Given a label, extent it to a descriptive sentence by crawling and filtering web texts
- Cluster BERT word embeddings to get word clusters
- Lexico-Semantic similarity: sentence similarity + word similarity(in the same cluster)
- contrastive learning(first filter then sample: filter the obvious unrelated one to accelerate)
Deduplicating Training Data Makes Language Models Better
- About deduplicating training datasets.
- methods:
- Exact match: use Suffix Array.
- Approximate match: first use MinHash, then use ‘edit distance’ to further filter. Link similar documents. Any connected documents are considered as similar.
Toolformer: Language Models Can Teach Themselves to Use Tools
- Use language model to convert a dataset into a new dataset which contains api calls
- Compare the PPL of a sentence before and after adding api calls to filter the new dataset.
- Finetune the language model on the filtered dataset
- It contains some prompts.
Learning Performance Improving Code Edits
- Curate a dataset with slow-fast program pairs(come from OJ, the same user’s different submission with respect to one problem)
- Use large language model to optimize programs.
- Use CodeX to do few-shot learning
- Fine-tune CodeGen
Symbolic Discovery of Optimization Algorithms
- Lion: a new optimizer, better than Adam. Require smaller learning rate, only track 1st momentum. And use sign of the interpolation of momentum and gradient to update parameters.
- search program space to find a algorithm:
- define some basic functions
- in every search step, add or delete a function or parameter
- prune the space by deleting invalid states and doing hashing
- validate the program on tasks step by step(first surpass the baseline of small tasks, then test it on larger tasks)
Neural Machine Translation of Rare Words with Subword Units
- Byte Pair Encoding(BPE): a method between word level and character level, to generate vocabularies
- divide words into characters
- use 2-gram to choose the most frequent pair, merge it and add it to the vocabulary
Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery
- generate hard prompts for texts and pictures by optimization
PromptCap: Prompt-Guided Task-Aware Image Captioning
- use few-shot learning to synthesize training data from large language models. Then filter the data to ensure the quality.
A parallel corpus of Python functions and documentation strings for automated code documentation and code generation
- a dataset of 300,000 python functions and docstrings
- release python script of scraping Github public resporitories
- a python scraper
AlphaCode
- pretrain on Github, finetuning on CodeContest Dataset
- Transformer decoder-encoder: encoder uses masked prediction and decoder uses next token prediction
- sample millions programs from model, then filter and cluster
BERT
- transformer encoder pretrained with masked token prediction and next sentence prediction
Language Models are Few-Shot Learners(GPT3)
SELECTIVE ANNOTATION MAKES LANGUAGE MODELS BETTER FEW-SHOT LEARNERS
- a method that helps to choose examples for in-context learning
- use SentenceBERT to put all samples into a vector space
- use cosine similarity and language model’s confidence as metric to choose top-k samples
- manually annotate choosed samples
- when choosing examples for in-context learning, again use SentenceBERT to map the data into vector space and choose the k-nearest neighbors.
Parameter-Efficient Transfer Learning for NLP
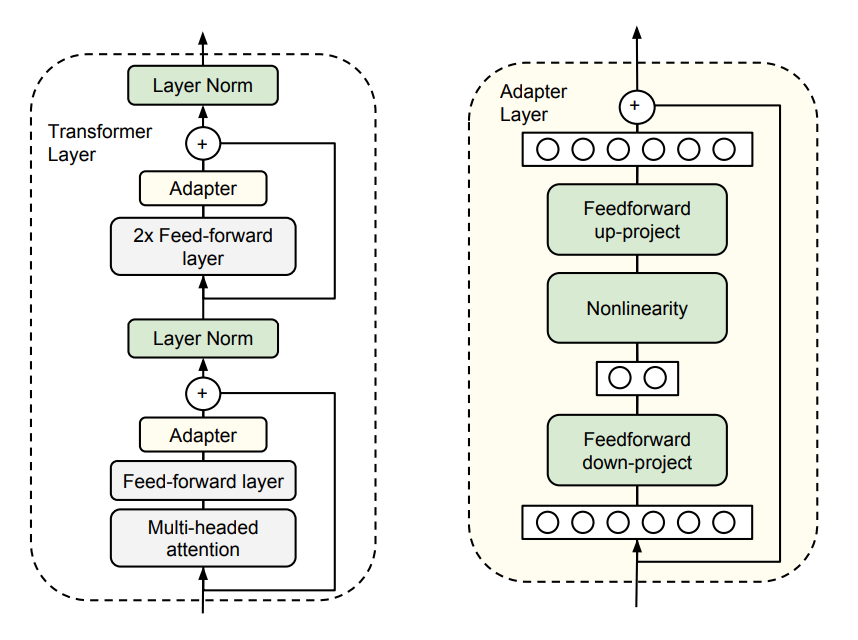
- add trainable adapter to pretrained transformer layers
- the parameters are initialized to near-zero. With the help of residual connection, the adapter is an approximate identical function(otherwise the training will fail)
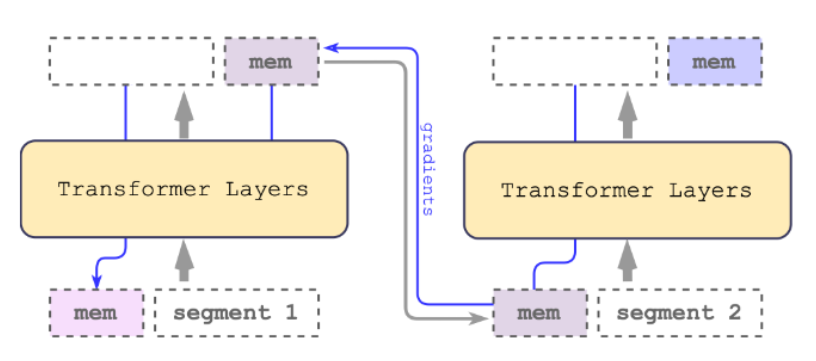
- RMT: recurrent memory transformer
- curriculum learning: first converge on simple problems and iteratively increase the difficulty
- In RNN, every unit takes one token. In RMT, we can view every unit as a transformer block.
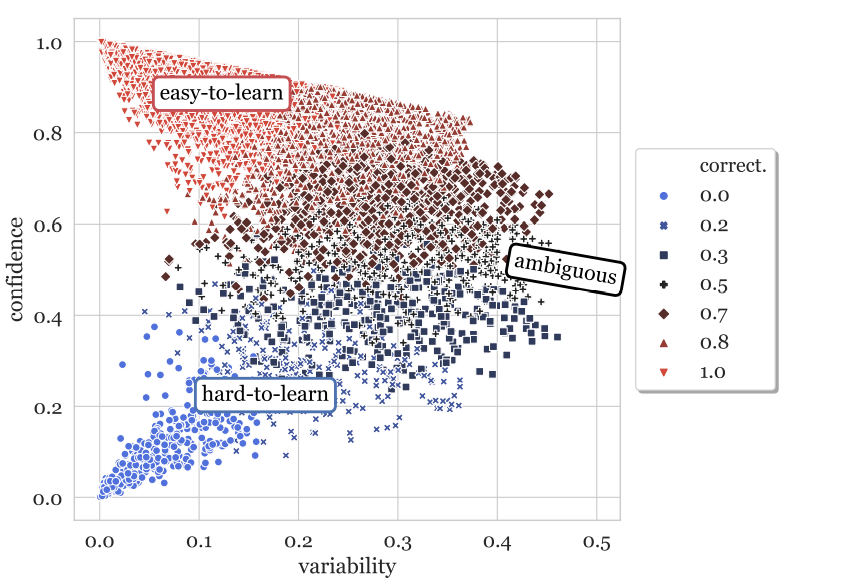
Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics
- A method to estimate data quality
- During training process, we record the confidence of the gold label for every training record in every epoch.
- Calculate the mean and variability for every record
- Every record can be clasified into one of the three fields